
flink 의 fault tolerance
flink 는 데이터 스트림을 stateful 하게 처리할 수 있는 프레임워크입니다. flink 는 checkpoint 를 통해서 데이터와 이와 함께 생성된 state 들을 효과적으로 장애를 복구(fault tolerance)할 수 있는 메커니즘을 제공하고 있습니다.
checkpoint
checkpoint 는 state 와 해당하는 stream position 의 Snapshot 을 주기적으로 저장하고 다시 시작할 수 있게 함으로써 flink 안에서 처리되는 state 가 장애복구될 수 있도록 합니다.
Snapshot 은 flink job 의 상태에 대한 image 로 kafka 의 오프셋과 같이 data source 들의 pointer 와 각 job 의 stateful operator 들의 state 의 복사본을 저장합니다. checkpoint 는 애초에 프레임워크가 관리하는 것으로 job 이 실행되는 동안 n-most-recent checkpoint 만 유지됩니다.
checkpoint 는 S3 혹은 HDFS 와 같은 persistent storage system 에 저장되고 따로 설정하지 않으면 job 이 cancelled 되면 삭제됩니다. 재배포, 업그레이드, 스케일링과 같은 목적으로 사용자나 API call 등에 의해 사람이 직접 트리거하는 스냅샷인 savepoint 와 는 다릅니다.

how does it work?
checkpoint 는 asynchronous barrier snapshotting 방식을 사용합니다. taskmanager 가 checkpoint coordinator 로 부터 checkpoint 를 시작하라는 지시를 받으면 checkpoint barrier 가 stream 으로 흘러가고 barrier 가 도착하면 각 operator 들은 해당 checkpoint 에 해당하는 snapshot 을 만들어 저장합니다. checkpointing 은 asynchronous 하게 진행되고 snapshot 이 진행되는 동안 stream 흐름이 방해받지 않고 계속 처리될 수 있도록 state 는 copy-on-write 메커니즘을 사용합니다.
Checkpoint 에서 exactly once 의 의미
stream 처리 중, operator 에서 exception 이 발생하는 등의 flink job 의 실패가 발생하고 다시 시작하게 된다면, stream 을 흐르는 event 는 누락되거나 중복처리될 수 있습니다. flink 의 CheckpointingMode 아래 모드를 모두 지원합니다.
- at most once: 복구를 위한 아무 조치를 취하지 않음
- at least once: event 누락이 없도록 조치, 중복 처리 가능성이 있음
- exactly once: event 의 누락이나 중복 처리가 없도록 함
장애 복구를 위해 flink 는 source data stream 을 re-play 합니다. 여기서 exactly once 가 이상적으로 보이지만, exactly once 는 모든 event 가 딱 한번만 processing 된다는 것을 의미하지 않습니다. 모든 event 가 state 에 한번만 처리되고 반영된다는 것을 의미하고, re-play 과정에서 external api call 을 수행하는 operator 등이 있으면 exactly once 모드더라도 같은 event 에 대해 여러번 호출될 수 있다는 것을 의미합니다.
end-to-end exactly-once
exactly once 모드라 하더라도 데이터를 외부 데이터베이스에 저장하는 Sink 가 있다면, 장애 복구가 일어날 경우 해당 데이터베이스에 중복된 데이터가 저장될 수 있습니다. 이처럼 flink 외부 시스템까지 exactly-once 를 확장하는 것을 end-to-end exactly-once 라고 합니다.
idempotent (멱등성)
외부 시스템이 멱등성을 보장한다면, 이는 비교적 간단하게 해결될 수 있습니다.
kafka → flink → db 의 데이터 흐름이 있다고 가정해보겠습니다. kafka 의 offset, partition 정보를 db 에 제약조건으로 같이 저장하고, 중복된 데이터를 저장할 시 실패하도록 처리하면 flink 에서 장애 복구가 발생하여 일부의 데이터가 중복으로 sink 로 흘러가도 db 제약 조건 자체로 이를 방지할 수 있습니다.
elasticsearch 에 위 offset+partition 조합과 같이 source 에서 차용할 수 있는 unique 값으로 id 를 생성하여 PUT 메소드(idmpotent)를 통해 document 를 저장해도 같은 효과를 볼 수 있습니다.
외부 시스템 idempotent 의존의 한계
만약, flink job 에서 aggregation 등의 연산으로 새로운 데이터를 생성하여 sink 로 전달하는 상황이라면 어떨까요?
외부 시스템이 멱등성을 보장하더라도, 이런 source 에서 유래하는 unique 값으로 멱등성을 보장하기 위한 id 값을 만들고 사용할 수 없을 것입니다.
aggregation 에 사용된 데이터들의 id 들을 모아서 외부 시스템의 id 값을 만드는 것을 상상해볼 수도 있습니다. 하지만 KeyBy 와 같은 operation 이 없고 n parallelism 으로 실행되거나 시간 단위로 aggregation 을 수행한다면 항상 같은 데이터가 같은 곳에서 처리되고 저장된다는 것을 보장할 수 없습니다.

Two phase commit (2PC)
2PC 란?

Two-phase commit protocol 은 모든 참여자가 원자적인 트랙잭션을 보장하기 위한 분산 알고리즘입니다. 여러 노드의 database 의 트랜잭션을 coordinate 하는 모습을 보이는데, 여기서 참여자는 flink checkpoint 와 외부 시스템이라고 볼 수 있습니다.
2PC 는 commit 단계에서 실패하면 계속 재시도해서 성공시켜야만 하는 단점이 있습니다.
2PC in Flink
end-to-end exactly once 를 지원하기 위해 flink 에서는 two phase commit 프로토콜을 사용합니다. two phase commit 을 사용하면 모든 record 들이 operator 에 commit 되는 것을 보장할 수 있습니다. task 들은 final checkpoint 가 성공적으로 완료될 때까지 기다립니다. final checkpoint 는 모든 operator 가 checkpoint 의 마지막 데이터가 처리되고 트리거됩니다.
즉. 데이터가 외부 시스템에 commit 되어야만 checkpoint 를 저장하는 것이라고 볼 수 있습니다.
two phase commit 을 사용하기 위해서는 외부 시스템이 two-phase commit protocol 의 Transaction 을 지원해야 합니다.
Fault Tolerance Guarantees of Data Sources and Sinks 에서 각 sink connector 들이 어떤 Gurantees 까지 지원하는지 확인할 수 있습니다.
| Sink | Guarantees | Notes |
| Elasticsearch | at least once | |
| Opensearch | at least once | |
| Kafka producer | at least once / exactly once | exactly once with transactional producers (v 0.11+) |
| Cassandra sink | at least once / exactly once | exactly once only for idempotent updates |
| Amazon DynamoDB | at least once | |
| Amazon Kinesis Data Streams | at least once | |
| Amazon Kinesis Data Firehose | at least once | |
| File sinks | exactly once | |
| Socket sinks | at least once | |
| Standard output | at least once | |
| Redis sink | at least once |
Two-phase commit 단계
Two-phase commit 는 Pre-commit 그리고 Commit 단계가 있습니다.
Pre-commit

스냅샷을 저장하면서 외부 시스템 Transaction 에 pre-commit 을 진행합니다. checkpoint barrier 가 모든 operator 를 통과하고 snapshot callback 가 모두 complete 되면 pre-commit 단계가 끝나게 됩니다.
만약 하나의 pre-commit 이라도 실패한다면, 모두 abort 되고 이전의 checkpoint 로 roll-back 됩니다.
Commit

jonmanager 로부터 모든 checkpoint 가 성공했다는 notify 를 받으면 Two-phase commit 의 commit 단계가 수행됩니다.
pre-commit 이 성공적으로 끝나면, commit 단계는 무조건 성공적으로 수행되어야 합니다. 만약 네트워크 등의 이슈로 commit 이 실패하면, restart strategy 에 따라 재시작되고 commmit 을 다시 시도하게 됩니다.
이는 Two-phase protocol 자체의 한계로, 이를 보장하지 않으면 data loss 가 발생할 수 있습니다.
Playground
at least once 의 중복 처리 확인
Checkpoint exactly once 모드에서도 실제로 checkpoint 중간의 데이터가 장애 복구에서 중복 처리되는지 확인해보도록 하겠습니다. 공식문서에 있는 Flink Operations Playground 를 통해 kafka → flink → kafka 흐름의 stream 을 구동해보겠습니다. page 를 담은 event 를 생성하는 kafka source 가 있고 이를 window 사이즈만큼 event 를 aggregation count 하여 kafka sink 로 보내는 job 입니다.
원활한 확인을 위해 checkpoint interval 은 10초이고, 5초의 window 로 수정하였습니다.

5초마다 데이터가 sink 로 전달되고 checkpoint 는 10초 마다 수행되니, 중간에 실패가 발생하면 10초전 checkpoint 부터 다시 re-play 되어 중복된 데이터가 sink 로 전달될 것입니다.
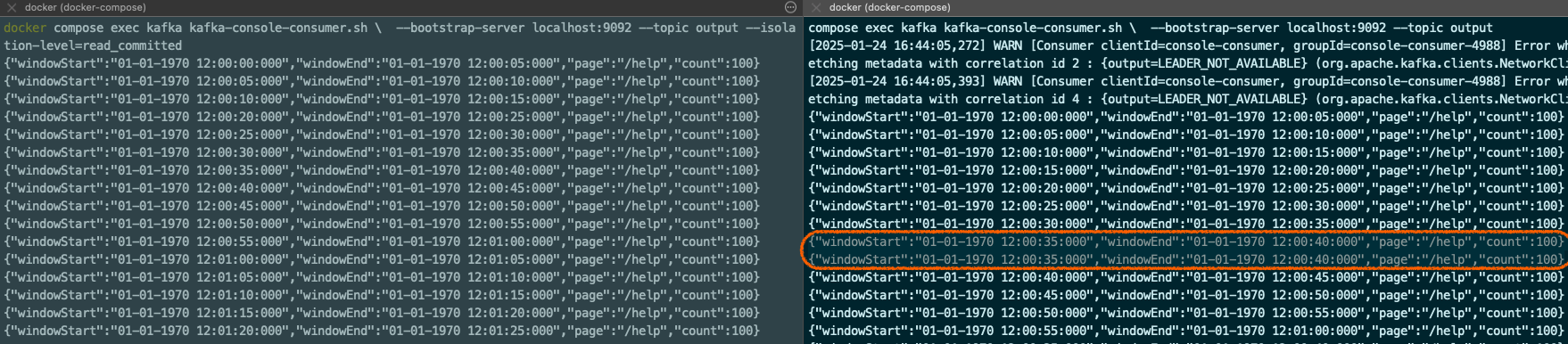
taskmanager 를 강제로 kill 하고 다시 띄우면서 중복 데이터가 sink 로 전달되는 것을 볼 수 있었습니다.

KafkaSink) DeliveryGuarantee.EXACTLY_ONCE
KafkaSink 의 DeliveryGuarantee.EXACTLY_ONCE (DeliveryGuarantee) 는 kafka 의 transaction 을 사용하고 checkpoint 마다 commit 됩니다.
kafka consumer 의 isolation-level 을 read_committed 하면 commit 된 data 만 읽는 것을 확인할 수 있고, read_uncommitted 와 달리 중복처리되지 않는 것을 확인할 수 있습니다.
장애 상황에서 flink 가 restart 되어 재개될 때까지 uncommitted transaction 이 살아있어야 하므로 maximum checkpoint duration + maximum restart duration 보다 크게 kafka transaction timeout 을 설정해야 합니다.
statistics.sinkTo(
KafkaSink.<ClickEventStatistics>builder()
.setBootstrapServers(kafkaProps.getProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG))
.setKafkaProducerConfig(kafkaProps)
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic(outputTopic)
.setValueSerializationSchema(new ClickEventStatisticsSerializationSchema())
.build())
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // 2PC 사용
.build())
.name("ClickEventStatistics Sink"); docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output --isolation-level=read_committed
JdbcSink) DeliveryGuarantee.EXACTLY_ONCE
MySQL 이나 PostgreSQL 등 database 가 XA 표준을 지원한다면, Java 의 분산 트랜잭션을 의한 XA interface 을 사용한 Jdbc driver 를 통해 exactly-once JdbcSink 를 사용할 수 있습니다.
public JdbcSink<ClickEventStatistics> createJdbcSink() {
return JdbcSink.<ClickEventStatistics>builder()
.withQueryStatement(
"INSERT INTO click_event_statistics (window_start, window_end, page, count) VALUES (?, ?, ?, ?)",
statementBuilder)
.withExecutionOptions(
JdbcExecutionOptions.builder().withMaxRetries(0).build())
.buildExactlyOnce(
JdbcExactlyOnceOptions.defaults(),
this::getXaDataSource);
}
private PGXADataSource getXaDataSource() {
PGXADataSource xaDataSource = new org.postgresql.xa.PGXADataSource();
xaDataSource.setUrl("jdbc:postgresql://postgres:5432/mydatabase");
xaDataSource.setUser("myuser");
xaDataSource.setPassword("mypassword");
return xaDataSource;
}
private final JdbcStatementBuilder<ClickEventStatistics> statementBuilder = (statement, stats) -> {
statement.setTimestamp(1, new java.sql.Timestamp(stats.getWindowStart().getTime()));
statement.setTimestamp(2, new java.sql.Timestamp(stats.getWindowEnd().getTime()));
statement.setString(3, stats.getPage());
statement.setLong(4, stats.getCount());
};
PostgreSQL, MySQL 등 connection 당 하나의 XA Transaction 을 허용하는 데이터베이스를 위해 아래와 같이 옵션을 제공합니다. 1대1 특성에 따라, XA Transaction 사용은 db 의 max_connections 값 조정해야할 수 있습니다. 또한, JdbcExecutionOptions.maxRetries == 0 를 설정해야 exactlyOnce 를 보장할 수 있습니다.
JdbcExactlyOnceOptions.builder()
.withTransactionPerConnection(true)
.build();JdbcSink Two-phase protocol 로그 확인
아래 로그를 보면 checkpoint 가 시작되면 prepare 단계를 수행하고 snapshot 이 모두 완료되면 commit 단계로 이어지는 것을 확인할 수 있습니다.
taskmanager-1 | 2025-01-24 09:55:01,962 DEBUG org.apache.flink.streaming.runtime.tasks.StreamTask [] - Starting checkpoint 3 CheckpointType{name='Checkpoint', sharingFilesStrategy=FORWARD_BACKWARD} on task ClickEventStatistics Sink: Writer (1/1)#0
taskmanager-1 | 2025-01-24 09:55:01,972 DEBUG org.apache.flink.connector.jdbc.datasource.connections.xa.XaCommand [] - end, xid={"jobId":[-11,-57,-104,111,-19,74,42,-38,8,-109,79,102,67,-65,-126,-23],"subtaskId":0,"numberOfSubtasks":1,"checkpointId":2,"attempts":0,"restored":false}
taskmanager-1 | 2025-01-24 09:55:01,973 DEBUG org.apache.flink.connector.jdbc.datasource.connections.xa.XaCommand [] - prepare, xid={"jobId":[-11,-57,-104,111,-19,74,42,-38,8,-109,79,102,67,-65,-126,-23],"subtaskId":0,"numberOfSubtasks":1,"checkpointId":2,"attempts":0,"restored":false}
taskmanager-1 | 2025-01-24 09:55:01,975 DEBUG org.apache.flink.runtime.state.SnapshotStrategyRunner [] - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@96271f0, checkpointDirectory=file:/tmp/flink-checkpoints-directory/f5c7986fed4a2ada08934f6643bf82e9/chk-3, sharedStateDirectory=file:/tmp/flink-checkpoints-directory/f5c7986fed4a2ada08934f6643bf82e9/shared, taskOwnedStateDirectory=file:/tmp/flink-checkpoints-directory/f5c7986fed4a2ada08934f6643bf82e9/taskowned, metadataFilePath=file:/tmp/flink-checkpoints-directory/f5c7986fed4a2ada08934f6643bf82e9/chk-3/_metadata, reference=(default), fileStateSizeThreshold=20480, writeBufferSize=20480}, asynchronous part) in thread Thread[AsyncOperations-thread-1,5,Flink Task Threads] took 14 ms.
taskmanager-1 | 2025-01-24 09:55:01,975 DEBUG org.apache.flink.connector.jdbc.sink.writer.JdbcWriter [] - Committing org.apache.flink.connector.jdbc.sink.committer.JdbcCommitable@940a591 committable.
taskmanager-1 | 2025-01-24 09:55:01,975 DEBUG org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl [] - Task ClickEventStatistics Sink: Writer (1/1)#0 broadcastEvent at 1737712501975, triggerTime 1737712501946, passed time 29
taskmanager-1 | 2025-01-24 09:55:01,978 DEBUG org.apache.flink.connector.jdbc.datasource.transactions.xa.XaTransaction [] - commit 1 transactions
taskmanager-1 | 2025-01-24 09:55:01,979 DEBUG org.apache.flink.connector.jdbc.datasource.connections.xa.XaCommand [] - commit, xid={"jobId":[-11,-57,-104,111,-19,74,42,-38,8,-109,79,102,67,-65,-126,-23],"subtaskId":0,"numberOfSubtasks":1,"checkpointId":2,"attempts":0,"restored":false}
taskmanager-1 | 2025-01-24 09:55:01,980 DEBUG org.apache.flink.connector.jdbc.datasource.connections.xa.XaCommand [] - start, xid={"jobId":[-11,-57,-104,111,-19,74,42,-38,8,-109,79,102,67,-65,-126,-23],"subtaskId":0,"numberOfSubtasks":1,"checkpointId":3,"attempts":0,"restored":false}마치며
Flink 의 CheckpointMode 의 exactly once 를 보고 모든 데이터가 한번만 처리되고 sink 로 전달된다고 생각할 수 있습니다. 하지만 이 exactly once 의 의미는 Flink state 에 event(data) 가 최종적으로 한번 반영된 결과를 보장한다는 것이지, event 가 딱 한번만 processing 된다는 것을 의미하지 않습니다.
sink 까지의 end-to-end exactly once 를 보장하기 위해서는 sink 대상의 외부 시스템에 Two phase commit Transaction 을 지원해야 하며, 그럼에도 commit 단계의 실패는 data loss 를 일으킬 수 있다는 것을 고려해야합니다.